Aug 28, 2023
About deployment, evaluation, and testing of agents with Sully Omar, the CEO of Cognosys AI

Cognosys provides a closed-source UI for creating AI agents. Their vision is to develop an easy-to-use consumer-facing product to assist non-technical individuals in completing specific daily tasks.
We asked the founder of Cognosys, Sully Omar, about his experience with building a product for no-code users in the Agents space.
Users and Basic Architecture
Cognosys is a web-based version of AutoGPT/babyAGI working in "loops" - a series of tasks. The agent generates output based on provided objectives and iterates until completion. It puts high-level tasks into smaller ones, calls an LLM, and iterates until the task is done. The whole process takes a few seconds and requires zero coding.
Sully emphasizes that the crucial moment is the first trial of Cognosys. “The people that have found value within first experience with the agents, are the ones who become returning users.”
There are more options offered for the agent’s “specialization”.
“Currently, we are focusing on narrowing down the use cases to just a few,” explains Sully. “People find the biggest value in letting the agent dig into the internet.”
The agent for searching over the internet, similar to Perplexity AI, is currently the most popular one. The research agent takes an objective, conducts internet research, synthetizes it, and provides links to relevant sources.
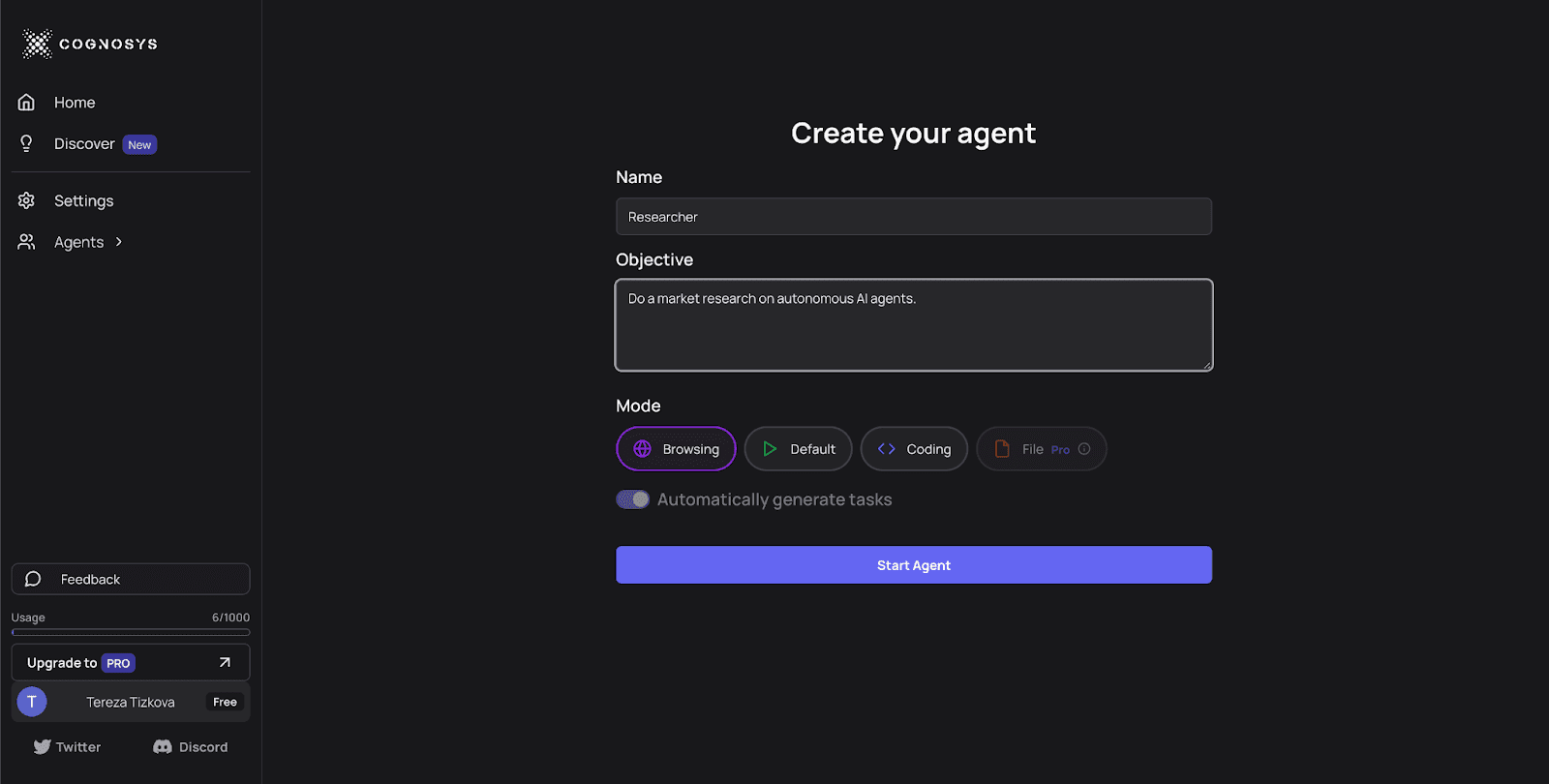
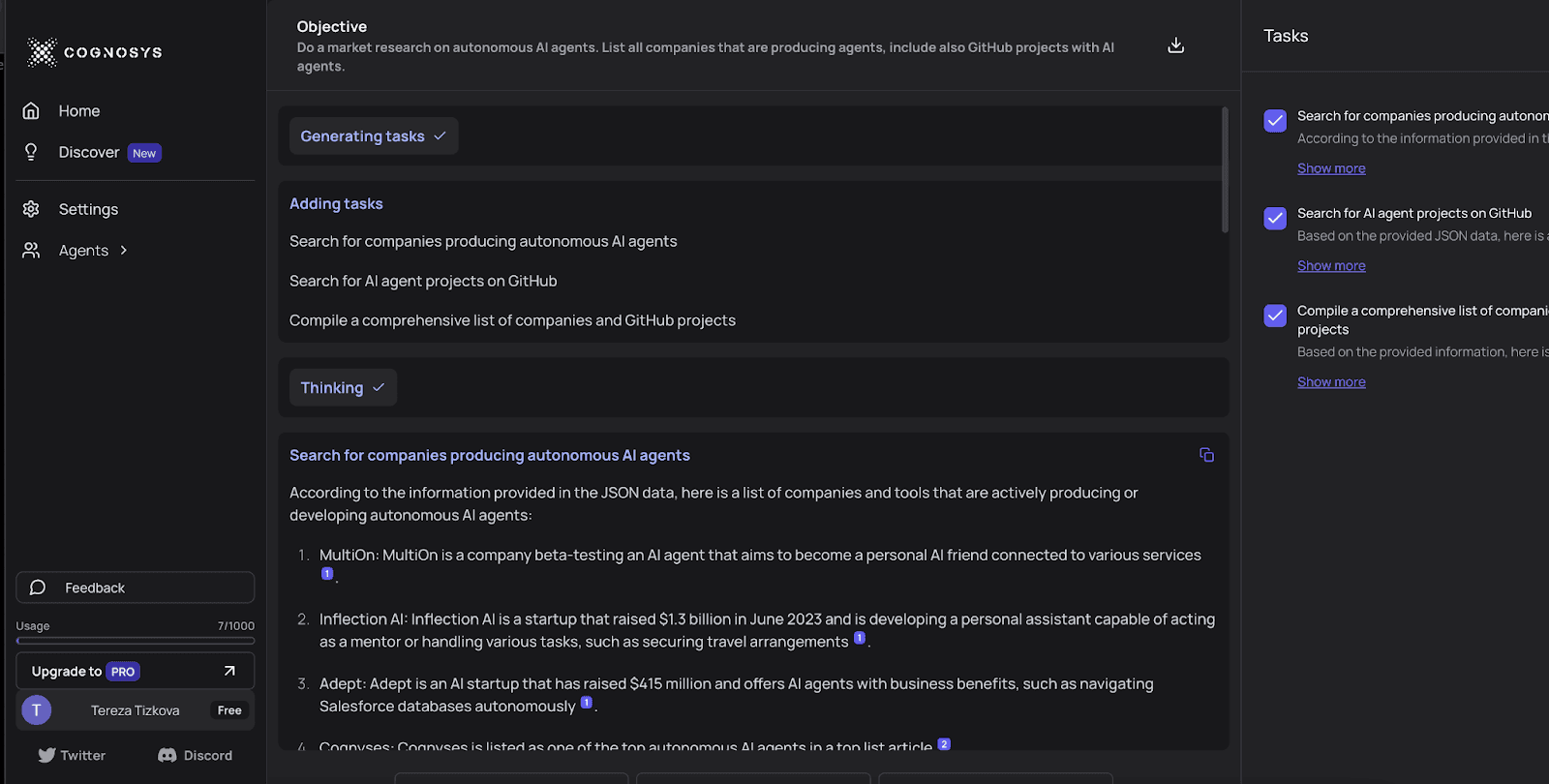
Source: https://app.cognosys.ai/
Overcoming Agents Challenges
Sully comments on the current problems of agent developers.
“Locally, monitoring of LLM agent’s steps is easy, but tracking what is happening at scale on the aggregate level is the most important challenge to solve, for any company using LLMs in general.”
For tracing agent runs, Cognosys uses mostly its own UI.
An important concern is how much information users should receive about the agents. According to Sully, for example, offering users a choice between GPT-3.5 and GPT-4 is useless if they do not understand which models are suitable for their needs. He believes that the primary concern of users is whether the agent can perform the expected tasks.
Deployment
The Cognosys team started by using the Vercel edge function, which had a limit of 60 seconds for a timeout. However, this posed a problem for Cognosys, since occasionally, the agent needs more time to execute.
They have tried Cloud Functions, which didn’t yield optimal results. Now they use an instance of Cloud Run that all main systems run on. “The advantage is that we get a unified API via an API Gateway for agents and can easily spin up tens of agents for a single user,”
There are issues that are associated with LLM calls in general. Serverless functions are meant to take 10-50 milliseconds. With LLM calls taking much more time, it doesn't make sense for Cognosys to use serverless architecture. They do use serverless for minor things, e.g. updating users’ profiles.
Observability
The Cognosys team is exploring a variety of tools, using different infra plugins for observability, which is a challenge due to multiple factors contributing to the success or failure of agents.
“We have tried Sentry, Google Cloud, Google Cloud Platform.” names Sully. “Another one we are starting to look at and that is agnostic to agents, but still in beta version, is Langsmith.”
The key aspect of observability is understanding which tools the agent uses throughout the process and whether they are the right choice.
Testing and Evals
“Evaluation is currently a big challenge for autonomous agents in general, due to the LLMs nature,” says Sully. “How do you define good output, especially for the longer and more complex runs requiring many steps, where we lack the simple input-output relation?”
We discussed how the subjectivity of good versus bad results is one of the root causes of agents' evaluation struggles.
“There are two parts to evaluate. The objective part to evaluate is the binary form, for example, whether the agent did, or didn’t order a meal or booked a flight. The other and more tricky part is to evaluate how well the agent wrote a text or how quality research it did.”
Debugging
Cognosys has its own system of the retrial of the agents’ steps when it fails. It notifies the end user by saying that the instance failed, and they can run the agent again.
They don’t share error details with end users. “Giving them too many insights can get the non-technical users confused,” says Sully. However, users are mostly able to solve the problems themselves, by simply reruning the agent.
Latency
In traditional SW engineering, around 200 milliseconds is considered slow. For AI agents in general, latency is a big issue, with LLM calls taking more than 30 seconds. Cognosys agents usually run anywhere from 60 seconds to even 5 minutes sometimes.
“Currently, the agent uses GPT-4, which takes quite a long time to take action,” says Sully. “But people expect results quickly, and waiting even a minute until an agent provides the result makes them unsatisfied.”
Conclusion
Sully realizes that the whole agents' space is still in the early phase.
“There is not that much functionality yet, so a big use-case at the beginning was just that the agent is fun to play with and try what it can do,” says Sully.
“But we want to continue focusing on a few valuable specializations for the agent. It’s very easy to want to do everything with the agent, but with the current models, it is impossible to do all these things well. And once the users get frustrated, they leave and never return.”
The Cognosys team is working on a new version of their platform. “We are excited about our next iteration that would solve some of the agents' issues, like latency”.
“Our plan for the future is to make the system more robust and easier to use, and have users more aware of capabilities.”