Oct 20, 2023
AI Agents vs Developers

We are E2B. We provide sandboxed cloud environments for AI-powered apps and agentic workflows. Check out our sandbox runtime for LLMs.
The traditional human-computer interaction now often involves an intermediary in the form of an AI assistant, which is specified by uncertainty. That is the root cause of many problems, but also brings many new possibilities and products.
Following the latest post on the State of AI Agents, I summarized the challenges of memory, security, testing, and data privacy of LLM products. I looked at how AI Engineers overcome these problems, e.g. with agent-specific products, and multi-agent frameworks.
I also asked the following LLM developers for their views and current approach to building:
Vasilje Markovic (founder of PromethAI)
Adam Silverman (co-founder of AgentOps)
Kevin Rohling (founder of BondAI)
Enjoy the reading!
Outline
There is a new ecosystem being formed
Security and data privacy must be addressed before enterprise adoption
RAG holds a central place in the discussing agents' memory
Testing AI products needs a special approach
Building may become more affordable
Inter-agent communication is becoming a major topic
Conclusion… so do agents work yet?
1. There is a new ecosystem being formed
The boom of new agents in the Summer of 2023 was followed by the development of frameworks, libraries, and tools that support their functioning.
Agents give AI apps new capabilities through a combination of reasoning and planning, self-reflection, tool usage, and memory.
In the emerging AI-centered ecosystem, LLMs are compared to kernel processes.

Fig 1. Andrej Karpathy's post on X. Source
Hundreds to thousands of people started to identify as AI Engineers, but millions more are needed to fulfill the growing demand, according to reports [1], [2]. A few days ago, San Francisco even hosted the first AI Engineer summit.
Relatively new LLM and agent-specific frontend and backend solutions, platforms for memory management, building frameworks, and SDKs are on the rise and are starting to work together.

Fig 2. Part of the ecosystem around LLM agents. Source
A great example of new products working together is
AgentLabs as an AI frontend with built-in Chat UI, attachments handler, and authentication
E2B as a safe sandbox runtime for executing code output
OpenAI’s GPT-4 as a model
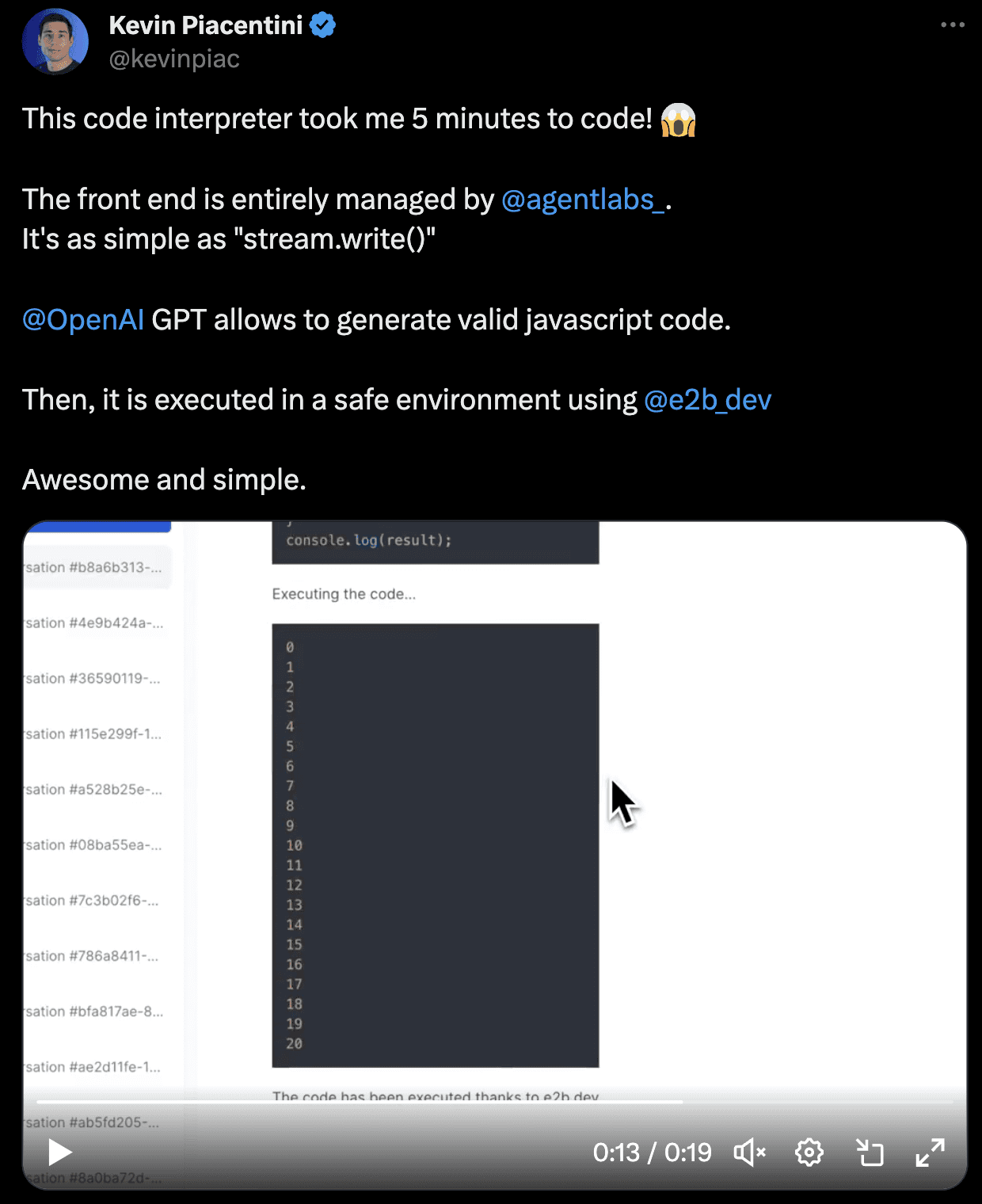
Fig 3. Example of new solutions for AI agents being applied together. Source
Similarly, you can build your code interpreter with Pyodide and Langchain, build agents with AutoGen and Chainlit UI, and many more. Even Langchain, the most popular agent framework, offers over 500 integrations.
2. Security and data privacy must be addressed before enterprise adoption
What are the outcomes of letting a LLM produce untrusted code run the user’s operating system?
A great example is the widely popular Open Interpreter which uses a terminal as an interface. The code doesn’t have to necessarily cause any irreversible damage. However, occasional uncomfortable outcomes still have been reported, for example, a GPT-generated command on pip install new package breaking the Open Interpreter dependency.
The big problem is making agents work in an arbitrary environment and runtime (custom environments). We need to be able to either execute the code securely or test whether the code is correct so LLM can fix itself.
José María Lago from GenWorlds adds to this:
“The challenge is having the right mix between deterministic and non-deterministic (agents’) routines. More mission-critical tasks require more deterministism. At GenWorlds, we allow the developer to choose where to draw that line.”
The challenges of untrusted code can be solved by running the code in secure cloud environments. If LLMs are a new kernel, then a cloud for running agents and AI apps is a new runtime.
Kevin Rohling, the founder of BondAI, thinks that in general, securing an agent isn't all that different than securing traditional software.
“For the products I've been developing, the security/code execution challenges are generally solved by running inside a heavily sandboxed Kubernetes node,” says Kevin.
“I highly restrict which outbound calls are allowed (e.g., obviously white list OpenAI), while I don't allow any inbound calls. I also heavily restrict what data the agent has access to.”
Data privacy and retention
Individual developers build chatbots using LLMs on private data. However, when it comes to the enterprise level, integrating AI solutions often requires an official legal data retention policy. It's not surprising that AI apps (with the most renowned ChatGPT at the forefront) are restricted or completely banned by many companies.
3. RAG holds a central place in discussing agents' memory
Recently, there has been hype [3], [4] around Retrieval Augmented Generation (RAG) as an efficient way to maximize the potential of LLMs without having to train your own. RAG combines retrieval and generation methods and its benefit for LLM apps is enabling developers to build on their private data.
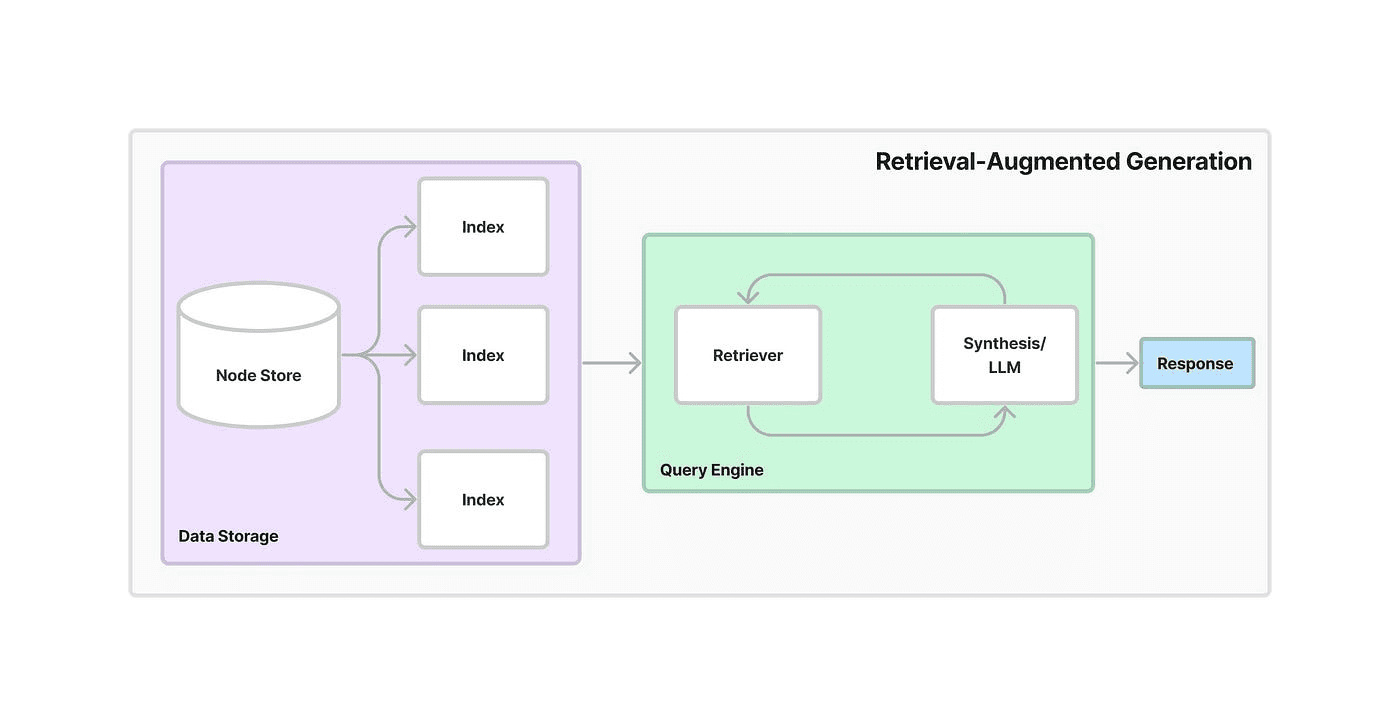
Fig 4. The RAG workflow. Source
If we compare “traditional” vector DBs, RAG, and large context windows, each has its own limitations.
Limitations of RAG
One unsolved problem for RAG is permissions, that is, figuring out which users are supposed to have access to what information in a chatbot or agent. Other potential challenges are a limited context window, having trouble utilizing the right data sources, or performing well in summary across the entire corpus.
Problems with vector databases
I discussed this topic with Vasilje Markovic, the founder of PromethAI, who is researching this topic.
“Vector databases have a problem with long upload times and can't handle loads. Retrieval doesn’t work as well, production needs dictate switching to something older that works,” says Vasilje. “A potential solution may be elastic search or relational databases.”
He adds that a pure semantic search doesn't add much value. “Since we are unable to understand dimensions such as time with only embeddings, we need to store more contextual information than just pure factual info.”
A big question analyzed in a new paper is whether vector databases are actually dangerous - it turns out that text embeddings can be inverted [5].
RAG vs finetuning vs longer context window
Unlike finetuning, RAG allows security and data privacy, because you can decide at any moment, what documents should you give access to.
Expanding LLM context windows is seen as a solution to hallucination [6]. However, recent studies [7] reveal LLMs' struggles to extract information from large contexts, especially when the information is buried inside the middle portion of the context. Moreover, costs increase linearly with larger contexts.
How to solve the problems
“Adding a series of memory abstractions powered by a "central LLM connector" fine-tuned to manage memory components coupled with a traditional DB or a Graph DB would be one approach to the issue,” says Vasilje from PromethAI.
Kevin from BondAI shares his own approach towards memory management:
“I created specialized agents that manage their own memory and I allow one "admin" agent to delegate tasks to those other agents,” comments Kevin. “This prevents a single agent from having to keep the whole problem context in memory at once. I also limit the maximum token size that any tool can respond with and architect my tools to prevent large files/content from polluting the memory space. A semantic search layer in the form of large documents helps a lot.”

Fig 5. Companies and open-source projects focused on AI agents' memory management. Source
4. Testing AI products needs a special approach
In the AI ecosystem, testing is crucial for ensuring quality code, just as in traditional software.
The co-founder and CPO of Codium, Dedy Kredo, gave a speech about how the industry's reliance on metrics such as code coverage is insufficient and can even be misleading, and the AI agents community needs to revolutionize our approach to testing.
Dedy believes that GAN-like architecture is the solution for testing AI-generated code. “GAN worked as two neural networks, one generating and one as a critic of the other. With transformers coming in 2017, the focus has been solely on the generative part.” [8]
Adam Silverman from AgentOps shared that the team at AgentOps is developing a test suite for agents that uses custom benchmarks in addition to WebArena, AG benchmark, and BOLAA.
We have written a lot about testing and talked to founders of agent-centered products, e.g. the founder of Lindy AI, founders of Sweep AI, or the founder of Superagent.
5. Building may become more affordable
Leaked updates by OpenAI say it is going to make AI-based software application development cheaper and faster. The changes are supposed to happen next month and should include adding memory storage to developer tools, potentially reducing application costs by up to 20 times. [9]
6. Inter-agent communication is becoming a major topic
In the past few months, end users started to take agents as something that does all the work for them.

Fig 6. Google search results
That is far from true. Instead of trying to create powerful multi-purpose agents, they have been becoming invisible” part of a more complex product.
Using multi-agent conversations with multiple agents, each focused on a specific topic working together on the same project can create opportunities for complex workflows. Examples of popular multi-agent frameworks are AutoGen by Microsoft, ChatDev, and GenWorlds.
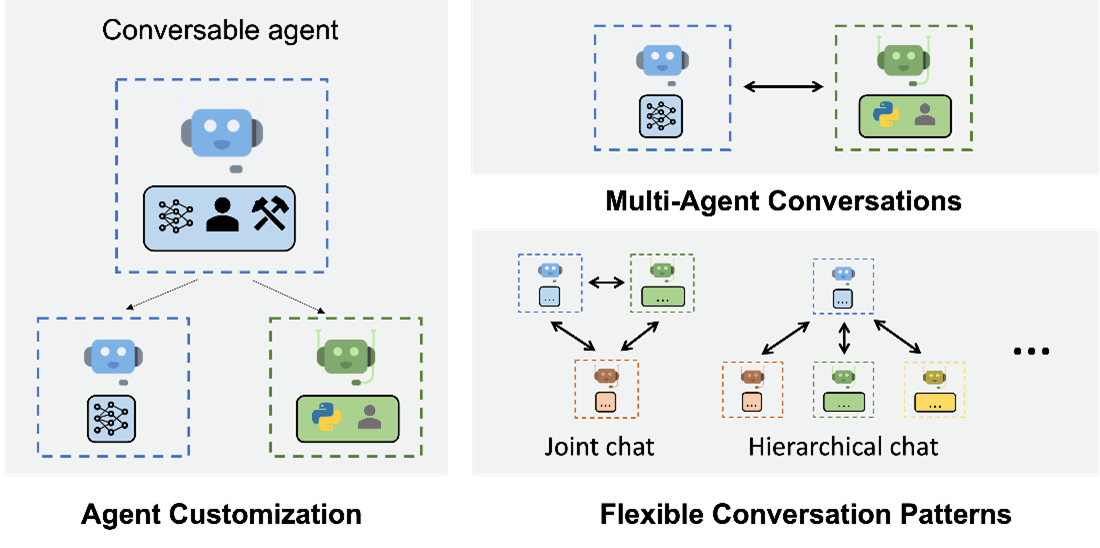
Fig 7. AutoGen agents’ workflow. Source
Overall, building agents’ frameworks is still a hard battle to win. The re-built solutions may be limiting in terms of tech stack. Even one of the most popular frameworks for agents' creation, Langchain, has struggled with criticism from the community, e.g. for the difficulty of setting up, too much abstraction, or no clear benefits.
In the end, for many developers, a simple solution like Python + OpenAI may be better. The agent frameworks may still be great for well-established workflows.
Does self-healing code work?
With the agents’ iteration and multi-agent communication, it is natural to ask about self-healing loops between agents.
However, a new paper from the Google DeepMind team shows that LLMs cannot “repair themselves” and achieve improvement through self-reflection, even with multiple agents.
"We investigate the potential of multi-agent debate as a means to improve reasoning. In this method, multiple instances of an LLM critique each other’s responses. However, our results reveal that its efficacy is no better than self-consistency when considering an equivalent number of responses, …"
However, AutoGen by Microsoft creates agents such that for example one writes a code, and another agent immediately debugs it, and it seems to work in examples and use cases. Also, GPT-4 becomes 30% more accurate when asked to critique itself. [10]
7. Conclusion… so do agents work yet?
Agents have the potential to become a central piece of the LLM app architecture, but they still struggle with being production-ready. [11]
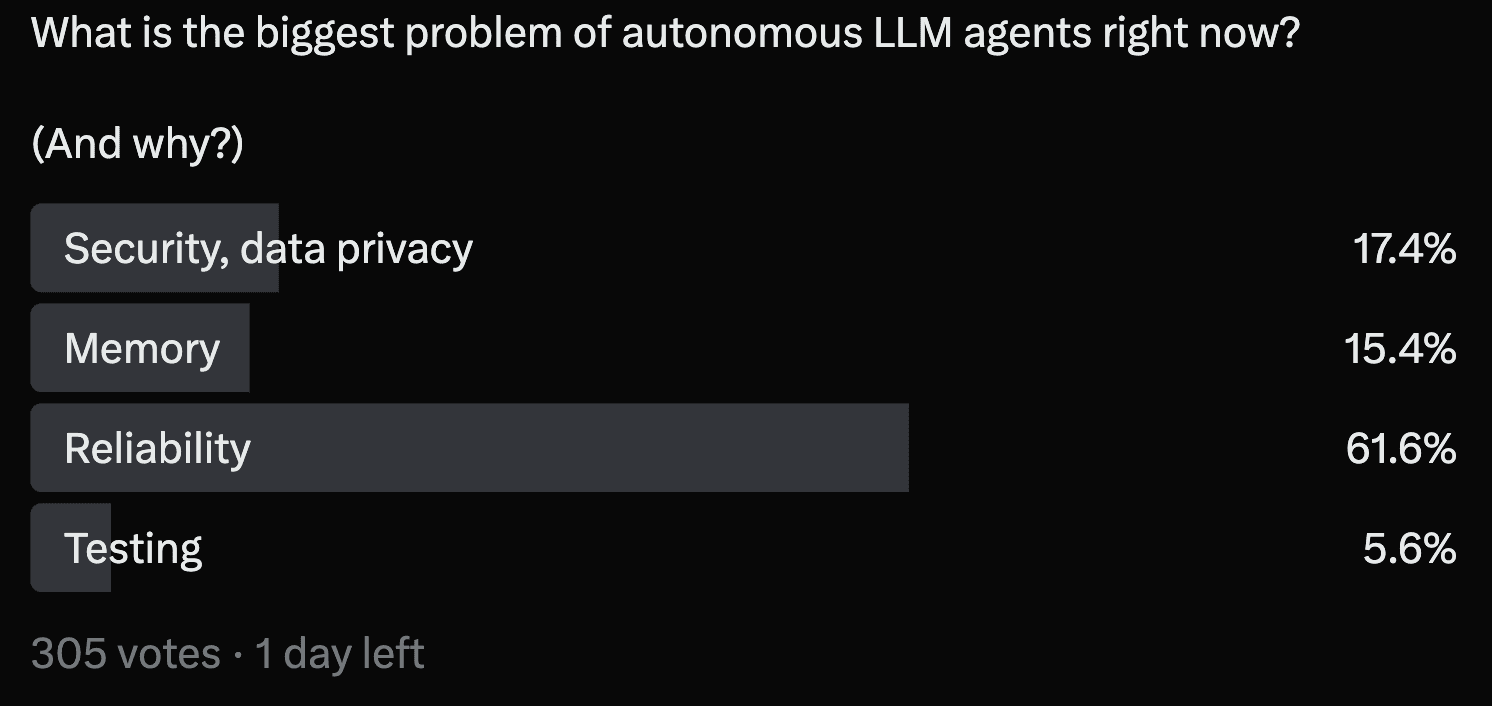
Fig. 8 A poll on X, asking developers for the current biggest problem of agents. Source
“I think the only successful agents are the ones that do really small things. So very specific, small things like fix the color of this button on the website or like change the color of this button,” says Kanjun Qiu, the CEO and co-founder of Imbue, in the Latent Space episode.
A use case that is already working well is agents for coding, including data visualization (e.g. SuperAgent, Cursor, Aide). As we discussed in a previous post, agents are directed toward becoming a small part of a more complex product.

Fig. 8 A post on X. Source
Hopefully, with LLMs consistently making progress toward better reliability, there is a bright future for agents. LLMs improve every few months, so consistency rises over time and becomes less of a worry.
Are you building AI agents, tools, SDKs, or frameworks and do you want to talk about your experience? Shoot us a message.
This post was written by E2B - sandbox runtime for LLMs. Any feedback and discussion is appreciated.
References
[1] The Verge (article)
[2] The New Stack (article)
[3] Latent Space (podcast)
[4] AI Engineer Summit (event page)
[5] Text Embeddings Reveal (Almost) As Much As Text (paper)
[6] Pinecone Blog (article)
[7] Lost in the Middle: How Language Models Use Long Contexts (paper)
[8] AI Engineer Summit (video, 25:00)
[9] Reuters (article)
[10] Reflexion: Language Agents with Verbal Reinforcement Learning (paper)
[11] A16Z (article)