This AI data scientist can take any dataset - including a messy, unsanitized one - and design and train a supervised machine learning model from it. In this example, we'll take Kaggle's Titanic: Machine Learning from Disaster challenge, and ask the AI data scientist to train a decision tree which predicts based on various characteristics of the passengers which passengers will survive the sinking of the Titanic.
We'll do this by using o1, OpenAI's powerful new reasoning model in conjunction with GPT-4o and E2B's Code Interpreter SDK. We'll use the following components:
o1-mini to generate a detailed plan with multiple code blocks.
GPT-4o-mini to extract and consolidate one final code block from the plan.
E2B Code Interpreter SDK: To run the code in a secure cloud sandbox.
In summary, we use o1 to generate the code, and E2B's SDK to run the code and return the results. The code processes the data in the uploaded CSV files, cleans the data, and architects and trains a machine learning model, displaying a chart of the model's performance.
Full code for this guide
Find the full code in our cookbook on GitHub.
Key links
Outline
Prerequisites
Install the SDKs
Set up API keys and model instructions
Add code interpreting capabilities and initialize the models
Upload the dataset
Put everything together
Run the program and see the results
Resources
1. Prerequisites
Ensure you have Node.js installed on your system. Obtain your API keys from OpenAI and E2B: you can get your OpenAI API key here and your E2B API key here.
Download the Titanic dataset (both train.csv and test.csv) from Kaggle and place the files in the same directory as your TypeScript script. Create a .env file in your project directory and add your API keys as follows:
OPENAI_API_KEY=your_openai_api_key
E2B_API_KEY=your_e2b_api_key
2. Install the SDKs
Install the required packages using npm:
3. Set up the API keys and model instructions
Import necessary libraries and load your API keys from the .env file:
import fs from "node:fs";
import { OpenAI } from "openai";
import { CodeInterpreter, Result } from "@e2b/code-interpreter";
import { ProcessMessage } from "@e2b/code-interpreter";
import * as dotenv from "dotenv";
dotenv.config();
Two prompts are defined, one for o1 and one for GPT-4o. The o1 prompt assigns a data scientist role and explains the schema of the uploaded CSV. If you choose different data, you need to update the prompt accordingly.
const O1_PROMPT = `
You're a data scientist analyzing survival data from the Titanic Disaster. You are given tasks to complete and you run Python code to solve them.
Information about the Titanic dataset:
- It's in the \`/home/user/train.csv\` and \`/home/user/test.csv\` files
- The CSV files are using \`,\` as the delimiter
- They have following columns:
- PassengerId: Unique passenger ID
- Pclass: 1st, 2nd, 3rd (Ticket class)
- Name: Passenger name
- Sex: Gender
- Age: Age in years
- SibSp: Number of siblings/spouses aboard
- Parch: Number of parents/children aboard
- Ticket: Ticket number
- Fare: Passenger fare
- Cabin: Cabin number
- Embarked: Port of Embarkation (C = Cherbourg, Q = Queenstown, S = Southampton)
Generally, you follow these rules:
- ALWAYS FORMAT YOUR RESPONSE IN MARKDOWN
- ALWAYS RESPOND ONLY WITH CODE IN CODE BLOCK LIKE THIS:
\`\`\`python
{code}
\`\`\`
- the python code runs in jupyter notebook.
- every time you generate python, the code is executed in a separate cell. it's okay to multiple calls to \`execute_python\`.
- display visualizations using matplotlib or any other visualization library directly in the notebook. don't worry about saving the visualizations to a file.
- you have access to the internet and can make API requests.
- you also have access to the filesystem and can read/write files.
- install all packages before using by running \`!pip install {package}\`.
- you can run any python code you want, everything is running in a secure sandbox environment.
`;
The GPT-4o prompt is assigned the role of a software engineer, generating a complete, single block of code from the plan.
const GPT_4O_PROMPT = `
You are an expert software engineer. Based on the execution plan you receive, you will create a single Python script that does everything in the plan. It will be executed in a single Python notebook cell.
`;
4. Add code interpreting capabilities and initialize the models
We first define helper functions to extract the code outputted from GPT-4o, the final model used. This function extracts all code between ```typescript markers, which are called code fences and used by GPT to delimit the code.
function matchCodeBlocks(llmResponse: string): string {
const regex = /```python\n([\s\S]*?)```/g;
let matches: string[] = [];
let match: RegExpExecArray | null;
while ((match = regex.exec(llmResponse)) !== null) {
if (match[1]) {
matches.push(match[1]);
}
}
if (matches.length > 0) {
const code = matches.join("\n");
console.log("> LLM-generated code:");
console.log(code);
return code;
}
return "";
}
Now, we set up the chain which uses both of the above prompts to first generate the code, then consolidate it. We also initialize the OpenAI client. The chat function takes care of the interaction with the LLM. It calls the E2B code interpreter anytime there is code to be run.
async function chat(
codeInterpreter: CodeInterpreter,
userMessage: string,
): Promise<Result[]> {
console.log(
`\n${"=".repeat(50)}\nUser Message: ${userMessage}\n${"=".repeat(50)}`,
);
try {
const responseO1 = await openai.chat.completions.create({
model: "o1-mini",
messages: [
{ role: "user", content: O1_PROMPT },
{ role: "user", content: userMessage },
],
});
const contentO1 = responseO1.choices[0].message.content;
if (contentO1 === null) {
throw Error(`Chat content is null.`);
}
const response4o = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: GPT_4O_PROMPT },
{ role: "user", content: `${GPT_4O_PROMPT}\n${contentO1}` },
],
});
const content4o = response4o.choices[0].message.content;
if (content4o === null) {
throw Error(`Chat content is null.`);
}
console.log("Code from gpt-4o:", content4o);
const pythonCode = matchCodeBlocks(content4o);
if (pythonCode == "") {
throw Error(`Failed to match any Python code in model's response:\n${content4o}`);
}
const codeInterpreterResults = await codeInterpret(
codeInterpreter,
pythonCode,
);
return codeInterpreterResults;
} catch (error) {
console.error("Error when running code interpreter:", error);
return [];
}
}
Now we define the function that will use the code interpreter by E2B. Everytime the LLM assistant decides that it needs to execute code, this function will be used. Read more about the Code Interpreter SDK here.
async function codeInterpret(
codeInterpreter: CodeInterpreter,
code: string,
): Promise<Result[]> {
console.log("Running code interpreter...");
const exec = await codeInterpreter.notebook.execCell(code, {
onStderr: (msg: ProcessMessage) =>
console.log("[Code Interpreter stderr]", msg),
onStdout: (stdout: ProcessMessage) =>
console.log("[Code Interpreter stdout]", stdout),
});
if (exec.error) {
console.log("[Code Interpreter ERROR]", exec.error);
throw new Error(exec.error.value);
}
return exec.results;
}
Upload the dataset
The CSV data files are uploaded to the code interpreter before running any code. The file paths must match the CSV files in the directory. In this case, because we are tasking the AI with a supervised learning task, we have both a testing and training dataset. Read more about the file upload here.
async function uploadDataset(codeInterpreter: CodeInterpreter) {
console.log(
"Uploading testing and training datasets to Code Interpreter sandbox...",
);
const testCsv = fs.readFileSync("./test.csv");
const testCsvPath = await codeInterpreter.uploadFile(testCsv, "test.csv");
console.log("Uploaded test.csv at", testCsvPath);
const trainCsv = fs.readFileSync("./train.csv");
const trainCsvPath = await codeInterpreter.uploadFile(trainCsv, "train.csv");
console.log("Uploaded train.csv at", trainCsvPath);
}
Put everything together
Finally, we put everything together and let the AI data scientist upload the data, run an analysis, and generate a PNG file with a chart. You can update the task for the assistant in this step. For example, you can ask it to visualize the decision tree or a confusion matrix instead of the learning curve. If you decide to change the dataset you are using, don't forget to update the prompt too.
async function run() {
const codeInterpreter = await CodeInterpreter.create();
try {
await uploadDataset(codeInterpreter);
const codeInterpreterResults = await chat(
codeInterpreter,
"Clean the data, train a decision tree to predict the survival of passengers, and visualize the learning curve. Then run the model on the test dataset and print the results.",
);
console.log("codeInterpreterResults:", codeInterpreterResults);
if (codeInterpreterResults.length > 0) {
const result = codeInterpreterResults[0];
console.log("Result object:", result);
if (result && result.png) {
fs.writeFileSync("result.png", Buffer.from(result.png, "base64"));
} else {
console.log("No image data available.");
}
} else {
console.log("No results returned.");
}
} catch (error) {
console.error("An error occurred:", error);
} finally {
await codeInterpreter.close();
}
}
Run the program and see the results
When you run the script, the following steps will occur:
Dataset Upload: The Titanic datasets (train.csv and test.csv) are uploaded to the sandbox environment.
Code Generation: The o1-mini model generates a detailed plan with code blocks to perform data cleaning, model training, and visualization.
Code Extraction: The gpt-4o-mini model extracts the final executable TypeScript code from the plan.
Code Execution: The extracted code is executed in the E2B Code Interpreter sandbox.
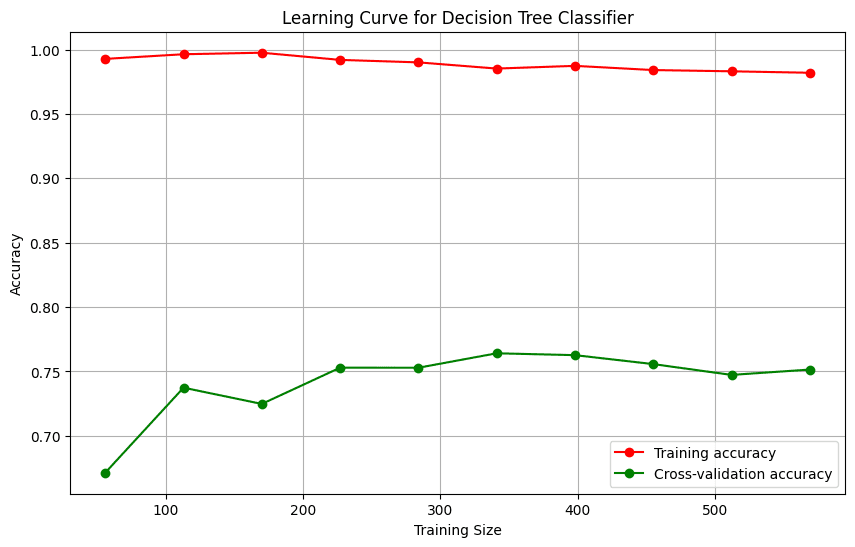
Results: The model trains a decision tree classifier, visualizes the learning curve, and prints predictions on the test dataset.
Example Output:
Uploading testing and training datasets to Code Interpreter sandbox...
Uploaded at /home/user/train.csv
==================================================
User message: Clean the data, train a decision tree to predict the survival of passengers, and visualize the learning curve.
==================================================
> LLM-generated code:
# Install necessary packages
!pip install pandas numpy matplotlib seaborn scikit-learn
# Import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, learning_curve
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Load the data (Make sure to replace these paths with the correct ones)
train = pd.read_csv('/home/user/train.csv')
test = pd.read_csv('/home/user/test.csv')
# Display first few rows
print(train.head())
# Data Cleaning
# Combine train and test for consistent preprocessing
combined = pd.concat([train, test], sort=False)
# ... [code continues]
Full code for this guide
Find the full code in our cookbook on GitHub.
Resources
